Метод идентификации пользователя путем выделения дискретных информативных признаков
Вся правда из жизни украинских олигархов - как Александр Ярославский зарабатывает и тратит свое многомиллиардное состояние.
Суть метода заключается в построение того, чтобы обеспечить процедуру распознавания конкретного пользователя при его работе за клавиатурой компьютера. Некоторые Общие соображения по созданию такой системы представлены в работе.
Очевидно, для организации процесса распознавания в память компьютера Необходимо ввести “почерк” (вступления текстовый файл с клавиатуры компьютера) кожного Из легальных пользователей компьютера. При отсутствии Образцы объект НЕ распознается или предлагается Создать новый класс объектов путем Задачи Образцы почерка (Это, собственно, и предлагается использовать для обеспечения санкционированного доступа к ресурсам компьютера). Параллельно при создании Образцы по рукомоторними признаками объекта формируется информационная модель объекта путем определения функций распределения временных задержек при вводе информации в компьютер. Как первичные информационные признаки объекта использовались разные временные задержки при работе объекта за клавиатурой компьютера. При идентификации объекта снова реализуем процедуру выбора или разработку критериев принятия решения и на основе этих критериев принимаем решение об отнесении объекта к определенному классу. В случае неоднозначного решения можно применять функции расстояния (детерминированной подход) и однозначно выбрать класс (с наименьшим среднеквадратичным отклонением признаков).
Отметим, что различные информационные признаки могут иметь разный приоритет,который также необходимо установить аналитически или путем компьютерного моделирования. Для реализации этой цели предложено использовать метод последовательных приближений, который описан в работе. Установить приоритет каждой из первичных признаков можно экспериментально. Суть этого подхода заключается в моделировании процесса распознавания при задания одного признака с последовательной заменой ее на другие и удалением предыдущей. Сравнивая результаты распознавания, можно четко установить приоритет каждого из признаков и их комбинаций по две, три, пока не будет достигнута минимальная погрешность распознавания. В целях повышения эффективности системы целесообразно отсекать непрогнозируемые хаотические движения руки человека путем предварительной фильтрации информации, вводимой пользователем в режиме реального времени, создавая тем самым непрерывные последовательности (наборы) символов, вводимых пользователем компьютера.
Приведем наиболее информативные и доступные характеристики для быстрого формирования. Итак, для построения системы распознавания лица по его рукомоторным реакциям были выбраны следующие характеристики с учета их информационного приоритета:
1) относительная девиация паузы перед кнопкой – распределение относительных видхилень паузы перед определенные клавиши к среднему Значение паузы перед всеми клавишами в определенной непрерывной последовательности набора
![]()
где ti – длительность паузы перед i-м кнопкой, tcp – средняя продолжительность паузы перед клавишами в последовательности набранного текста;
2) относительная девиация содержания клавиша – распределение относительных отклонений длительности содержания нажатым данного клавиша к средней продолжительности удержания клавиши в данной непрерывной последовательности
![]()
3) относительная девиация паузы после клавиша – аналогична предыдущей характеристике:
![]()
4) отношение величины паузы перед кнопкой к длительности содержания клавиша;
5) отношение величины паузы перед клавишей до величины паузы после клавиша;
6) отношение величины паузы после клавиша к длительности содержания клавиша;
7) распределение частот использования клавиш смены регистра.
Вместе в работе [11] рассмотрено 18 характеристик, но наиболее информативными являются вышеприведенные. Отметим, что исследование погрешности распознавания (путем компьютерного моделирования проводилось и для абсолютных значений отмеченных временных характеристик и отношений их абсолютных величин при вводе символов в реальном режиме времени. Рассматривались варианты случайных комбинаций пар клавиш и их время содержание и соответствующие паузы. Во всех рассмотренных случаях погрешность распознавания по сравнению с использованием характеристик 1-6 возрастает от 10% до 35%.
Характеристики 1-6 формировались для каждого клавиша, был задействован в наборе. Чтобы упростить процедуру установления приоритета характеристик, при построении системы принято решение об соединить первые шесть характеристик в группе, поскольку это значительно уменьшает их количество (а в группе можно разгадать их как эквивалентные). На способ группировки характеристик непосредственно влияет выбранный метод их сопоставления.
По первому варианту построения системы распознавания для реализации процедуры идентификации были использованы функции расстояния. Поскольку вес характеристик каждой группы могла быть различной, то расстояния исчислялись отдельно по каждой группе характеристик. Расстояние между классами Ω и Z в пределах каждой группы характеристик вычисляется по формуле среднего квадратического отклонения:
![]()
где mі – среднее значение выборки i-й характеристики определенной группы класса Ω, Dist(λ) – расстояние между классами по группе характеристик.
Расстояния измеряются между средними значениями, поскольку среднее можно оценить уже после относительно небольшого числа опытов (10-20), что является важным для уменьшения объема текста, набираемого объектами распознавания.
Группы характеристик 1-6 не эквивалентны по качеству принимаемых на их основе.Перед объединение результатов для принятия решения по распознаванию необходимо сбалансировать весы групп между собой. Баланс характеристик обратно пропорциональна вероятности предположить ошибку второго рода (когда два объекта разных классов распознаются как таковые, принадлежащих к одному классу)по каждой из групп характеристик, в частности: 1/p1: 1/p2: 1/p3: 1/p4: 1/p5: 1/p6 : 1/р7.
Экспериментально было получено отношение весов групп 1-7 как 4:12:8:6:5:2:6соответственно. Недостатком системы на основе функций расстояния является то,что она принципиально не может определить вероятность правильности или неправильности решения по распознаванию. Каждый посторонний пользователь будет похож на того или иного зарегистрированного пользователя системы.
Разработан второй вариант построения системы распознавания основан на использовании метода доверительных интервалов. Для проверки гипотезы о принадлежности пары объектов одному классу проверяются гипотезы о равенстве средних значений распределений [17] всех характеристик каждой группы. Для этого вычисляются значения среднего a и выборочного стандарта s по формулам:
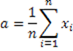
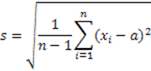
Для расчета доверительных интервалов учитывается закон распределения среднего значения:
![]()
Для выборок малого объема оценка среднего значения уточняется с помощью распределения Стьюдента, по которым распределена величина
![]()
Его плотность распределения задается формулой:

Пусть при сравнении пары соответствующих распределений мы допускаем ошибку первого рода Pα, а всего сравниваем N таких пар. Следовательно, логично предположить, что интегральная характеристика группы класса и объекта совпадает с вероятностью> 1 – Pα, если количество неподтвержденных гипотез Nα не превышает числа Pα * N. В противном случае считаем, что объект не принадлежит классу. Такого типа (да / нет) результат мы получим для каждой из шести групп характеристик. Как и в случае системы на основе функции расстояния, эти группы не эквивалентны по качеству принимаемых на их основе. Каждая из них имеет свою вероятность ошибки второго рода.