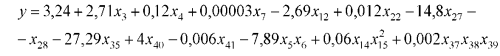Построение модели ранжирования поисковой выдачи Google (начало)
Во допустим вы заказали создание сайта визитки, предварительно узнали сколько стоит сделать сайт. А дальше вам необходима раскрутка сайта. Выполнение раскрутки необходимо поручать исключительно опытным специалистам, которые понимают всю суть работы поисковых систем и их особенности.
В данной задаче моделируем процесс ранжирования веб-ресурсов поисковой выдачи системы Google для поисковой фразы «веб-программирование».
Для эксперимента было отобрано первых 50 сайтов поисковой выдачи по данному ключевому запросу. Матрица исходных данных X содержит 42 признака-фактора, которые численно характеризуют каждый сайт (см. ниже). Столбцы матрицы X соответствуют значениям факторов, а строки – веб-ресурсу. Выходной величиной у является порядок ранжирования результатов выдачи, т. е. номер сайта.
Для моделирования применяется обобщенный итерационный алгоритм ОИА МГУА, в котором матрица данных X делится на две части: первая (примерно 2/3 длины) – обучающая А, которая используется для оценки коэффициентов моделей, вторая (1/3 длины) – проверочная выборка В, на которой вычисляется качество модели как значение критерия регулярности AR:
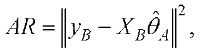
где ΘA – оценка коэффициентов модели с помощью МНК.
Для моделирования процесса ранжирования результатов поиска веб-ресурсов были использованы следующие признаки (входные переменные): х1 – количество ключевиков на сайте; х2 – количество ключевиков на странице; х3 – отношение общего числа слов к числу ключевых слов на сайте; х4 – отношение всего числа слов к числу ключевых слов на странице; х5 – Google Page Rank (далее PR, результат расчета авторитетности веб-страниц по алгоритму системы); х6 – популярность тематики; х7 – число запросов по конкретному ключевику за определённый период времени; х8 – общее количество страниц веб-сайта; х9 – объём текста сайта; х10 – объём сайта; х11 – объём текста веб-страницы; х12 – возраст сайта; х13 – наличие ключевого слова в URL сайта (имя домена); х14 – периодичность обновления сайта; х15 – последнее обновление страниц сайта; х16 – число рисунков на сайте; х17 – количество мультимедийных файлов; х18 – наличие замещающих надписей на картинках; х19 – число символов замещающих надписей картинок; х20 – использование фреймов; х21 – язык сайта; х22 – размер шрифта ключевых слов; х23 – жирность шрифта ключевых слов; х24 – написаны ключевые слова в разрядку или нет; х25 – написаны или нет ключевые слова заглавными буквами; х26 – расстояние ключевиков от начала веб; х27 – наличие ключевых слов в заголовке; х28 – наличие ключевых слов в мета-тэгах; х29 – наличие файла «robot.txt»; х30 – географическое месторасположение сайта; х31 – комментарии внутри html-кода сайта; х32 – к какому типу страниц относится каждая страница сайта: asp, html, php; х33 – наличие flash модулей; х34 – наличие веб-страниц с незначительными отличиями друг от друга; х35 – соответствие ключевиков сайта разделу каталога поисковой машины, в котором он зарегистрирован; х36 – наличие «стоп-слов»; х37 – общее количество гиперссылок сайта; х38 – количество внутренних гиперссылок сайта; х39 – количество внешних гиперссылок сайта; х40 – глубина сайта; х41 – количество внешних ссылок, содержащих в названии ключевые слова; х42 – индекс цитирования Яндекс (ТИЦ).
Выходной переменной у является позиция веб-ресурса среди результатов ранжирования поисковой выдачи системы. Точность построенной модели будем рассчитывать по формуле коэффициента детерминации:
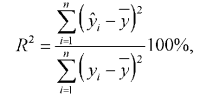
где y – среднее значение, yi – выход модели. С применением программной реализации ОИА МГУА была построена следующая модель, которая описывает результаты ранжирования веб-ресурсов в данной поисковой системе: