Исследование алгоритмов поисковых систем (окончание)
3. Проектирование системы анализа и моделирования исследуемых данных. Для проведения исследования методов поискового ранжирования, используемых в любой поисковой системе, используется программный комплекс, основанный на МГУА алгоритмах.
На рис. 1 представлена структурная схема основной части программного комплекса, с помощью которого будут проходить исследования факторов, влияющих на поисковую выдачу, а именно, будет построена модель ранжирования, на основе которой можно определить значимость факторов, а также спрогнозировать результаты поисковой выдачи (для нахождения модели используются оптимизации многорядного алгоритма МГУА). Существует два основных типа алгоритмов МГУА -комбинаторный и многоряный. Комбинаторный алгоритм МГУА реализует полный перебор всех возможных структур моделей, что занимает много времени, если входных переменных больше, чем 20. Для решения задач моделирования большой размерности необходимы алгоритмы укороченного перебора моделей. Одним из таких алгоритмов является классический многорядный алгоритм МГУА, который требует значительно меньшего количества времени для нахождения оптимальной модели.
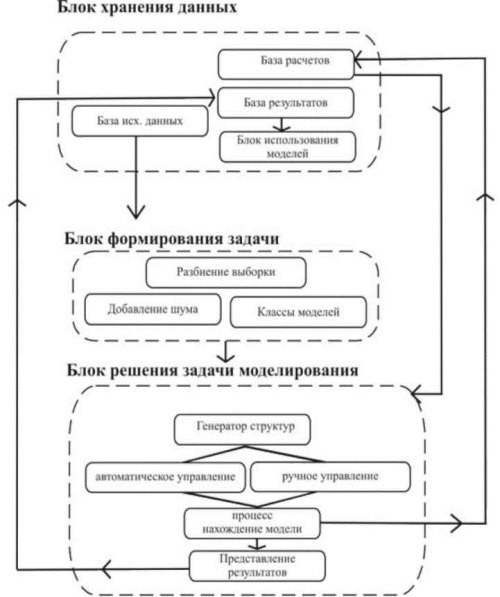
Рис.1 Построение прогнозной модели с использованием оптимизаций многорядного алгоритма МГУА
В данном исследовании присутствует большое количество входных переменных (больше чем 20), поэтому для решения поставленной задачи был выбран комбинаторный алгоритм и его модификации.
С помощью блока хранения данных, имея начальную выборку (сгенерированную или полученную из существующего файла), есть возможность разбивать данные на проекты, сохранять промежуточные расчеты, для дальнейшего продолжения процесса моделирования, сохранять результаты расчетов, а также использовать полученные модели на новых данных. Более детально блок хранения данных рассмотрен на рис.2.

Рис.2. Блок хранения данных
После того как начальная выборка сгенерирована или получена, мы переходим к блоку формирования задачи (рис.3.). На этом этапе выборка делится на две части: на учебную и проверочную. Учебная подвыборка нужна для оценивания параметров модели, а проверочная – для определения прогнозирующей способности модели.
При генерировании выборки данных есть возможность задавать: тип разбиения выборки; уровень шума, выбор класса модели.
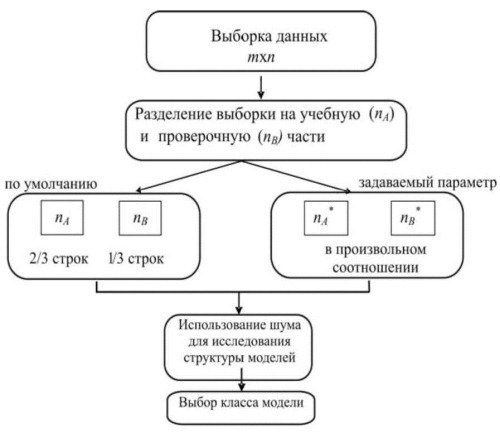
Рис.3. Блок формирования задачи (nA – длина учебной части выборки данных; nB – длина проверочной части выборки данных; )
Дальше, в зависимости от использования различных оптимизаций многорядного алгоритма МГУА, генерируются модели, различной сложности, для каждой из которой вычисляется значение критерия, по которому они отбираются для следующего слоя. В программном комплексе предусмотрено автоматическое управление и ручное управление. Ручное управление отличается тем, что на каждом слое можно изменять структуру сети.
После того как оптимальная модель будет найдена можно проверить, как ведет себя модель на новых данных, выполнить имитационное моделирование и использовать построенные модели для принятия решений.
Данный программный комплекс дает возможность:
-
самостоятельно конструировать методы моделирования по данным наблюдений;
-
сравнивать полученные модели по заданным критериям;
-
разрабатывать методики и планировать статистические испытания;
-
решать задачи моделирования;
-
проводить имитационные эксперименты с моделями, построенными по разным методам моделирования.
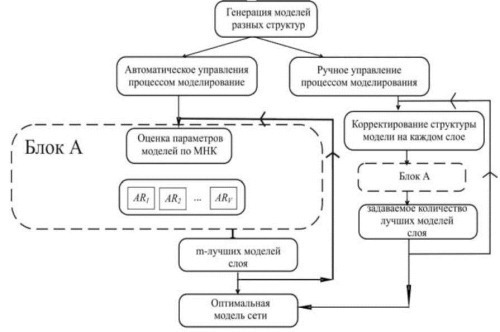
Рис.3. Блок решения задачи моделирования.
AR1,AR2,—,ARV – значение критерия регулярности для V лучших моделей.